
pandas简介
学习要点
- 了解pandas在数据分析过程中的作用
- 了解pandas安装及测试方法
- 掌握pandas中常见的数据结构
- 掌握Series的创建及各类操作
- 掌握DataFrame的创建及各类操作
学习内容
什么是pandas
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具和大量快速便捷地处理数据的函数与方法。
通过带有标签的列和索引,Pandas 使用户可以以一种所有人都能理解的方式来处理数据。它可以让用户毫不费力地从诸如 csv 类型的文件中导入数据。我们可以用它快速地对数据进行复杂的转换和过滤等操作。
pandas的安装方法
对于pandas来说,最小的依赖项集合如下所示。
(1)Numpy:处理数值数组的基础软件包。
(2)Python'datautil:一个专门用来处理日期数据的程序库。
(3)Pytz:一个处理时区问题的程序库。
上面列出的是最低限度的依赖项。对于使用Linux操作系统的用户,可以用PyPI程序来安装pandas,或者使用已经编译好的二进制形式的安装程序。此外,还可以借助操作系统的程序包管理器来安装pandas。
用pip程序安装pandas的命令如下。
$ pip install pandas pandas中的数据结构 pandas 中引入了两种新的数据结构:Series和DataFrame,这两种数据结构都建立在NumPy的基础之上。
Series
什么是Series
Series是一种一维的数据类型,其中的每个元素都有各自的标签。(与数组和字典的功能类似)
Series的创建
创建Series的方法如下:
Series([数据1,数据2,…], index[索引1,索引2,…])
Series常见操作
- Series内容的查看:如果想要分别查看组成Series对象的两个数组,可以调用它的两个属性:即values和index。
- Series的索引:Series的索引与数组的索引很相似,Series的元素需要使用索引值来访问。
- 更改Series元素:指定Series索引位置,即可以修改其对应的值。
- 追加Series元素:给Series追加元素,可以使用append方法。
- 删除Series元素:给Series删除元素,可以使用drop方法指定索引,也可以使用指定值删除。
Series元素的排序
- 使用sort_index()方法对索引进行排序
- 使用sort_values()方法对值进行排序
以上两个方法都包含ascending参数,其值为True为升序,其值为False为降序 在Series上调用reindex()方法重排数据,使得它符合新的索引,如果索引的值不存在,就引入缺失数据值。
DataFrame
什么是DataFrame
- DataFrame是一种列表式的数据结构。与Excel的电子表格或者关系型数据库的数据表非常相似。其设计初衷是实现多维的Series。DataFrame由按照一定顺序排列的多列数据组成,各列的数据类型可以有所不同。

- DataFrame还可以理解为一个由Series组成的字典。其中每一列的名称为字典的键,形成DataFrame的列Series作为字典的值。每个Series的所有元素映射到称为index的标签数组。
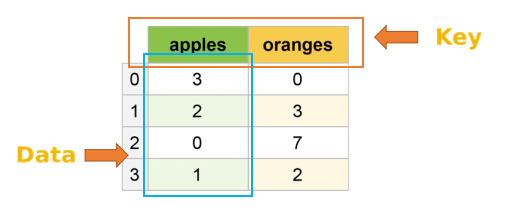
DataFrame的创建
DataFrame在创建过程中的注意点:
- 最常用的方法即是参照上述示意图,传递一个dict对象给DataFrame构造函数。dict对象以每一列的名称作为键,每个键都有一个数组作为值。
- 创建DataFrame时可以使用columns来指定需要的列。创建的DataFrame各列的顺序与指定的列顺序是一致的,与原字典中的顺序无关。
- DataFrame对象与Series一样,如果index数组没有明确指定标签,pandas也会自动为其添加一列从0开始的递增数值作为索引。如果想使用指定标签作为索引,则将标签放入数组中,赋给index即可。
DataFrame值的增加
- 可以使用insert函数。df.insert(0,'colName',seq) #colName表示新插入的列名,而seq是包含数值的序列
- 可以直接在df后加入列名,同时赋值。df['tomatos']=tomatos #默认在df最后一列添加内容
- 可以使用append函数。df.append(df_insert,ignore_index = True)
DataFrame值的查询
- 使用df['column_name'] 和df[row_start_index, row_end_index]
- 使用df.loc[index,column]
- 使用iloc[row_index, column_index]
DataFrame值的修改
- 改标题:使用df.columns = ['newName1','newName2']直接修改。注意点是要把所有的列全写上,否则报错。
- 改标题:使用df.rename()函数。df.rename(columns = {'XJ':'banana','PG':'apple'},inplace = True)
- 改数值:使用loc修改。df.loc[1,'apples'] = 9 #修改index为1,column为'apples'的那一个值为9。df.loc[1] = [19,21] #修改index为'1'的那一行的所有值
- 改数值:使用iloc修改。
df.iloc[1,2] = 19 #修改某一元素 df.iloc[:,2] = [11,22,33] #修改一整列 df.iloc[0,:] = [12,23,15] #修改一整行
DataFrame值的删除
1. 使用drop()函数删除。 df.drop([1,3],axis = 0,inplace = False)#删除index值为1和3的两行
2. 使用del删除。 del df['apples']